It’s been a while and fall has been very busy. I am working on z2 version 2.8 which will bring some very nice remote management additions to simplify managing a distributed application setup.That was the motivation behind this post.
This post is about a deployment approach for distributed software systems that is particularly useful for maintenance and debugging.
But let‘s start from the beginning – let‘s start from the development process.
Getting Started
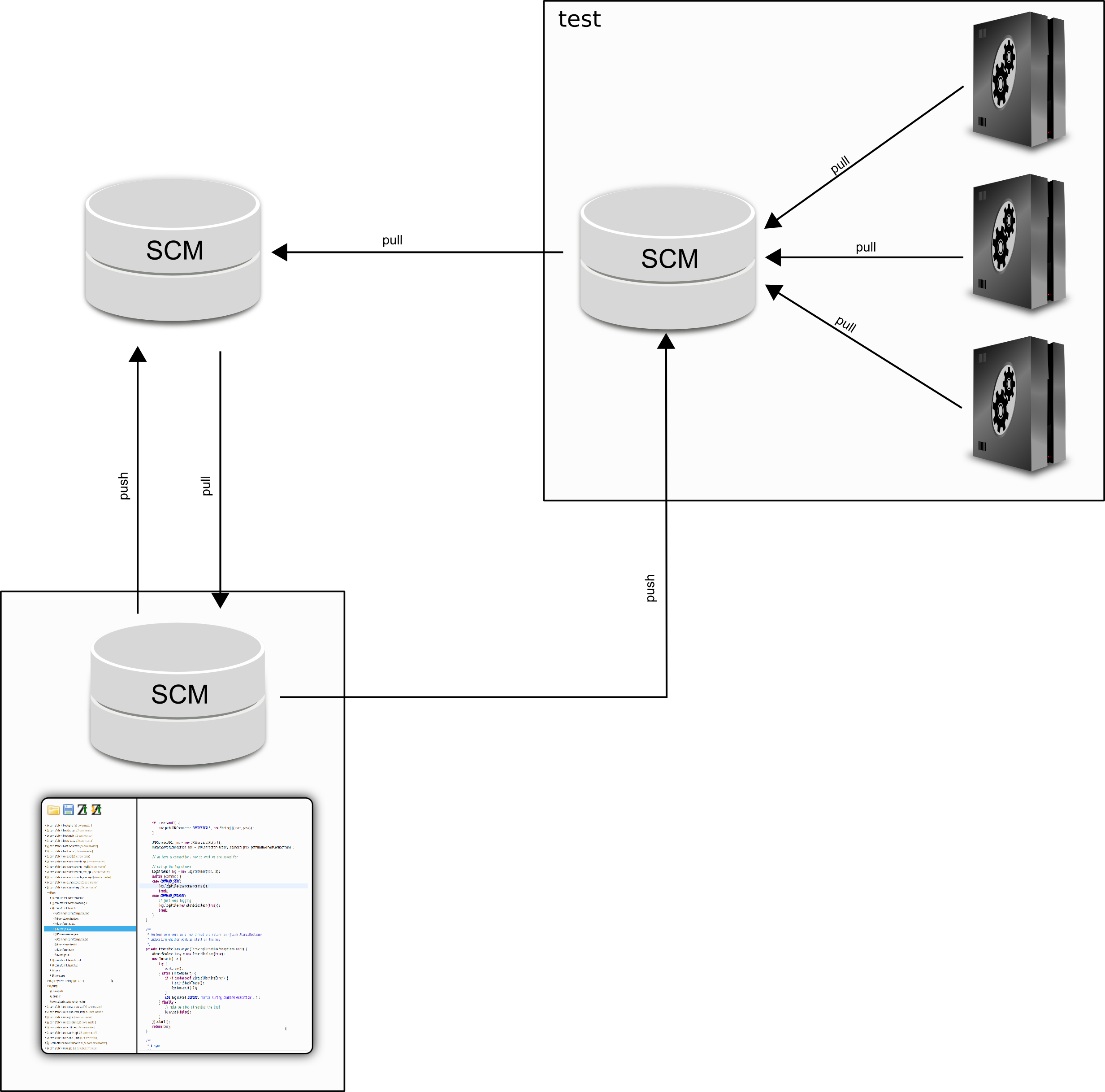
The basic model of any but the most trivial software development is based on checking out code and configuration from some remotely managed version control system (or Software Configuration Management system, SCM) to a local file system, updating it as needed and testing it on a local execution environment:

At least for the kind of application I care about, various versions, for development, testing, and productive use are stored in version control. In whatever way, be it build and deploy or pull, the different execution environments get updated from changes in the shared SCM. Tagging and branching is used to make sure that latest changes are separated from released changes. Schematically, the real situation is more like this:

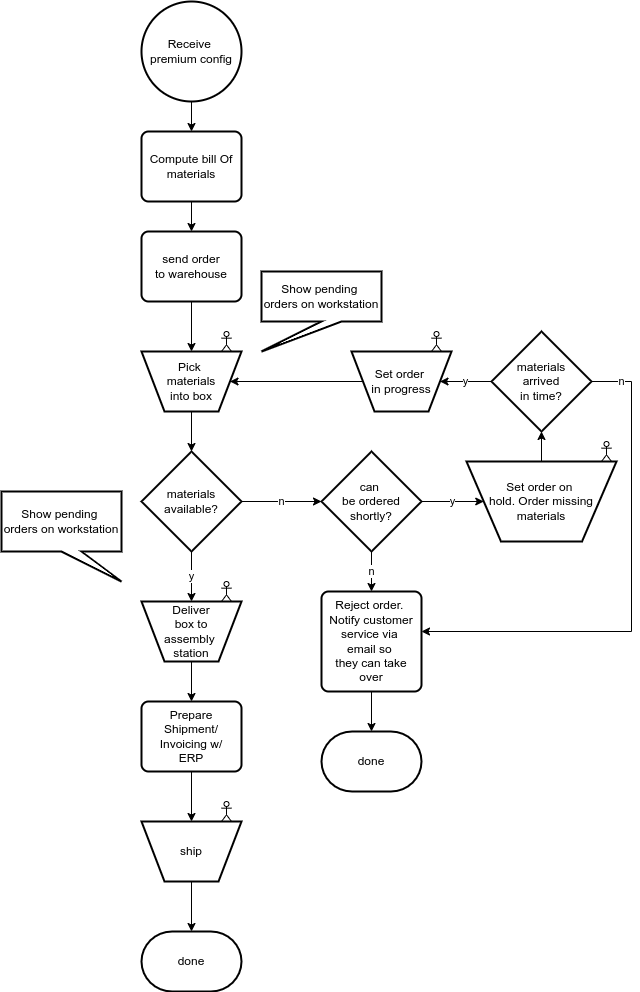
There are good reasons we want to have permanent deployments for testing and staging: In large and complex environment a pre-production staging system may consist of a complex distributed setup that integrates with surrounding legacy or mocked third-party systems and have corresponding configurations. In order to collaboratively test workflows, check system configurations, and test with historic data, it is not only convenient but really natural and to have a named installation to turn to. We call that a test system. But then:
How do you collaboratively debug and hotfix a distributed test system?
For compile-package-deployment technologies, you could setup a build pipeline and a distributed deployment mechanism that allows you to push changes you applied locally on your pc to the test system installation. But that would only be you. In order to share and collaborate with other developers on the test system, you need some collaborative change tracking. In other words, you should use an SCM for that.
Better yet, you should have an SCM as an integral part of the test system!
Using an SCM as Integral Part of the System
Here is one approach like that. We are assuming that our test system has a mechanism to either pull changes from an SCM or there is a custom build and deploy pipeline to update the test system from a named branch. Using the z2-Environment, we strongly prefer a pull approach – due to its inherently better robustness.
From a test system‘s perspective we would see this:

Here „test-system“ is the branch defining the current code and configuration of the test system deployment. We simply assume there is a master development branch and a release branch that is still in testing.
So, any push to „test-system“ and a following „pull“ by the test system leads to a consistently tracked system update.
Let‘s assume we are using a distributed version control system (DVCS) like Git. In that case, there is not only an SCM centrally and on the test system, but your development environment has just as capable an SCM. We are going to make use of that.
Overall we are here now:
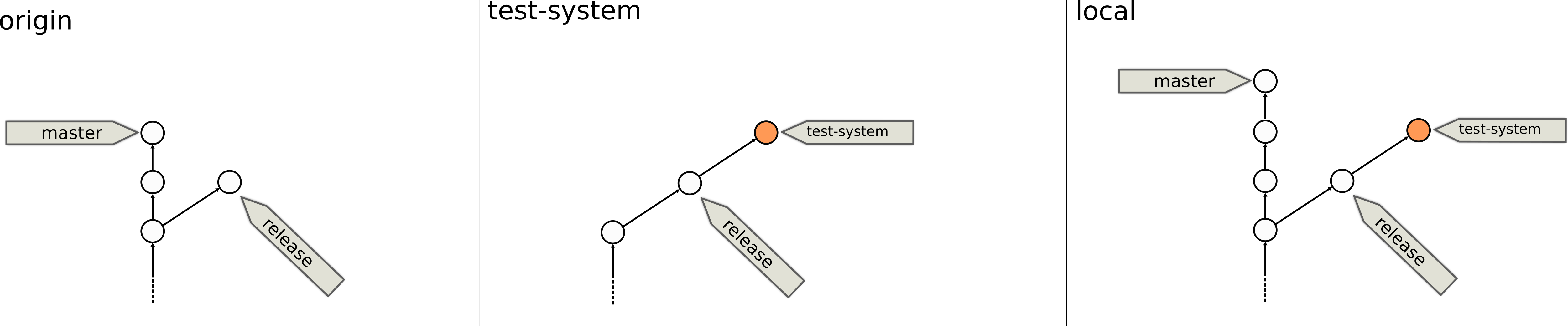
What we added in this picture is a remote reference to the test-system branch of the test system’s SCM from our local development SCM. That will be important for the workflows we discuss next.
The essence of our approach is that a DVCS like Git provides us a common versioning graph spanning multiple repositories.
Example Workflows
Let‘s play through two main workflows:
- Consistent and team-enabled update of the test system without polluting the main code line
- Extracting fix commits from test commits and consolidating the test system
Assume we are in the following situation: In our initial setup, we have a main code line (master) and a release branch. Both have been pushed to our central repository (origin). The test system is supposed to run the release branch but received one extra commit (e.g. for configuration). We omitted the master branch from the test-system repository for clarity. In our development repository (local), we have the master branch, the release branch as well as the test-system branch. The latter two from different remotes respectively. We have remote branches origin/master, origin/release, test-system/test-system to reflect that. We will however not show those here unless that adds information:
In oder to test changes on the test system, we develop locally, push to the test system repo and have the test system be updated from there there. None of that affects the origin repository. Let‘s say we need two rounds:

We are done testing our change with the test system. We want to have the same change in the release and eventually in the master branch.
The most straightforward way of getting there would be to merge the changes back into release and then into master. We did not write particularly helpful commit messages during testing however. For the history of the release and the development branch we prefer some better commit log content. That is why we are squash-merging the test commits the release branch and merge the resulting good commit into release.
After that we can push the release branch and master changes to origin:

While this leads to a clean history centrally, it puts our test system into an unfortunate state. The downside of a squash-merge is that there is no relationship between the resulting commit and the originating history anymore. If we would now merge the „brown“ commit into the test-system branch we would most likely end up with merge conflicts. That may still be the best way forward as it gets you a consistent relationship with the release branch and includes testing information.
At times however, we may want to „reset“ the test-system into a clean state again. In that case, we can do something that we would not allow on the origin repository: Overwrite the test-system history with a new, clean history, starting at where we left off initially. That is, we reset the test-system branch, merge the release commit, and finally force push the new history.

Now after this, the test system has a clean history that shows a history as we would have it when updating with release branch updates normally. None of what we did had any impact on the origin repository until we decided for meaningful changes.
Summary
What looked rather complicated was actually not more then equipping a runtime environment with its own change history and using some ordinary Git versioning „trickery“ to walk through some code and configuration maintenance scenario. We turned an execution environment into a long-living system with a configuration history.
The crucial pre-requisite for any such scenario is the ability of the runtime environment to be updated automatically and easily from a defining configuration repository implemented over Git or a similar DVCS.
A capability that the z2-environment has. With version 2.8 we intend to introduce much better support for distributed update scenarios.