Manufacturing companies require increasingly complex skills to maintain production and optimize operations.
This is not just about saving costs, but also about having the expertise to implement complex and innovative improvements – beyond what suppliers have to offer.
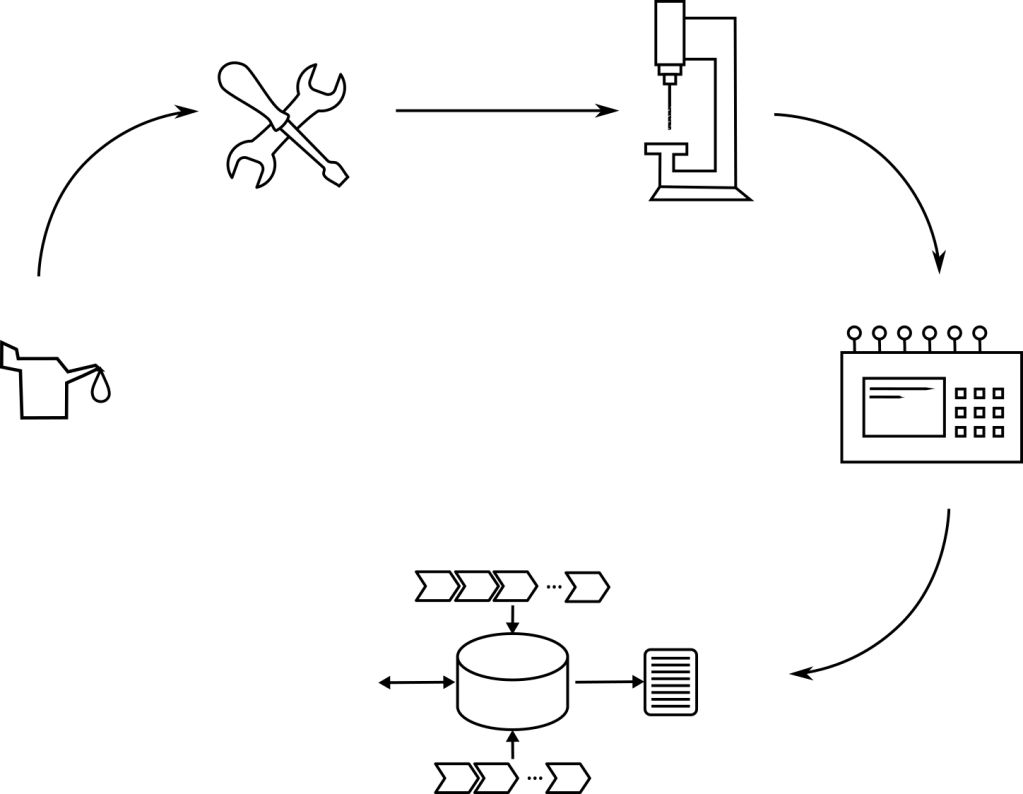
In the past, machines were bought for production and serviced by the supplier. Then operators realized that it was not only cheaper but also smarter to perform the maintenance oneself.
From the ability to carry out maintenance autonomously, it is not a far step to acquire the competence to modify, extend, and supplement machines in a way that aligns best with one’s business processes.
The exact same applies to business software today!
If you initially had industry solutions developed or bought them off the shelf and had them customized, now is the time to gain the expertise to expand, supplement or even modify the software yourself.
While this has always been explicitly possible with ERP solutions (especially SAP), and has been an absolutely critical factor in the long-term success of ERP providers, it is still the exception with other software.
However, especially for use in production and in connection with increasing automation, it is extremely relevant not only to combine software solutions with each other, but also to be able to modify existing solutions and, at best, to master them completely.
Only with the ability to “skillfully own” your software stack will it be possible to fully master operational processes in the future. And only then will it be possible to customize them as needed and design them for business success.
In dem Post Warum Individualsoftware? habe ich über die Vor- und Nachteile von Individualsoftware vs. Standardsoftware geschrieben.
In diesem Post geht es um On-Premise-Software, also vom Verwender selbst betriebene Kaufsoftware im Vergleich zu Software-as-a-Service-Software (SaaS) bzw. Mietsoftware – also Software, die vom Lösungsanbieter betrieben wird, und für die der Verwender ein Nutzungsrecht auf Online-Nutzung erwirbt.
Es wird vor allem darum gehen, welche Aspekte besonders wichtig für eine Entscheidung sind – vor und nach der Entscheidung.
Wenn es bei Warum Individualsoftware? um geschreinertes Regal vs. Billy-Regal ging, dann geht es hier gewissermaßen um Haus kaufen vs. Wohnung mieten – mit analogen Effekten.
Wesentliche Aspekte einer SaaS-Lösung sind:
Keine Investition
Die Anschaffung einer Software kann eine nicht unwesentliche Investition bedeuten. Bei gemieteter Software entfällt dieses Problem. So kann es sinnvoll sein, mit einer gemieteten Lösung zu starten, obwohl man sich bewusst ist, dass unten stehende Nachteile vielleicht später zuschlagen. Der Wert des einfachen Starts und möglicherweise auch die eingeschränkte Freiheit können helfen, genauer zu verstehen, wie der eigene Geschäftsprozess am besten umzusetzen ist.
Kein Betriebsaufwand
Weder muss Infrastruktur angeschafft noch betrieben werden. Es muss kein Ausfallplan und kein Backup erstellt werden. Die Gewährleistung der Verfügbarkeit der Lösung ist nicht ihr Problem (eine ungenügende Verfügbarkeit an sich aber vielleicht doch).
Bekommt die Software neue Feature oder Bug-Fixes und muss aktualisiert werden: Nicht ihr Problem.
Abhängigkeit: Kein Plan B, falls Angebot nicht mehr passt oder Anbieter geht.
Es gilt der alte Spruch: Daten leben länger als Software. In diesem Fall liegen ihre Daten beim Lösungsbetreiber. Kündigen Sie, können Sie womöglich Ihre Daten in irgendeiner Form herunterladen – ohne die fremde Software aber nur unter unklarem Aufwand damit weiter arbeiten (z. B. nach einer Migration für eine andere Software).
Flexibilität: What You See Is What You Get
Die gemietete Lösung ist nur so anpassbar wie sie entworfen wurde. Stellen Sie fest, dass ihr Geschäftsprozess schwer mit der Lösung umzusetzen ist, sind Sie auf das Wohlwollen ihres Anbieters angewiesen.
Integrierbarkeit: Keine Lokale Integration (sicher) möglich
Grundsätzlich stellt die Integration mit einer externen Lösung ein Sicherheitsproblem dar. Dabei geht es hier weniger um die Qualität der Netzwerkinfrastruktur oder ob diese lokal ist oder in der Cloud ist, sondern darum, dass möglicherweise sensible Daten Ihr Netzwerk über nicht von Ihnen abgesicherte Protokolle verlassen.
Es sind genau diese Aspekte, die eine Mietsoftware von einer Kaufsoftware unterscheiden. Vereinfacht und zur Illustration in Korrelation zur Individualsoftware stellen sich die Fälle ziemlich komplementär dar:
In den meisten Fällen sollte die Entscheidung einfach sein: Ist eines der Kriterien aus Abhängigkeit, Anpassbarkeit, Integrierbarkeit kritisch für den Geschäftszweck, so scheidet die fremd betriebene Mietsoftware aus. Das ist bei standardisierten Prozessen häufig nicht der Fall (E-Mail, Steuer, Personalabrechnung, …) aber zum Beispiel bei produktionsnaher Software (MES Systeme, Rework / Manuelle Workflows) meist doch.
Wenn man nun aber feststellt, dass die Software am besten lokal betrieben wird, was kann den Aufwand reduzieren?
Entscheidende Kriterien sind hier stets Komplexitätsgetrieben:
Komplexität der Installation
Ist die Installation komplex, zum Beispiel weil viele Fremdbibliotheken installiert werden oder Abhängigkeit an Elemente einer Betriebsystemversion bestehen oder muss gar eine Serverlandschaft aufgesetzt und abgesichert werden muss, so handelt es sich um eine Komplexitätskatastrophe mit Ansage.
Sind die Grenzen zwischen der gekauften Leistung und ihrer Betriebsumgebung schlecht definiert, so ist der Betrieb und seine Verantwortlichkeiten undurchschaubar und die Wartung entweder nicht vernünftig leistbar oder teuer.
Entsprechend finden wir:
Komplexität des Upgrades
Ist die Installation schon komplex, so kann davon ausgegangen werden, dass spätere Softwareversionen durch neue Abhängigkeiten und damit Veränderungen innerhalb des komplexen Setups nur noch komplizierter und damit unverständlicher und in der Folge teurer werden.
Komplexität der Software-Logistik
In der Königsklasse, nämlich der kundenspezifisch integrierten, erweiterten, möglicherweise sogar angepassten Software, kommt neben den beiden Punkten oben noch die Komplexität der Softwarelogistik hinzu. Zum Zeitpunkt der Anpassung und Aktualisierung der Software muss stets gewährleistet sein, dass verstanden wird, welche Änderungen wann vorgenommen wurden, ob Erweiterungen und Anpassungen kompatibel sind und wie diese qualifiziert werden können. Das bedeutet, dass die Entwicklung und die Quellcodeverwaltung der Kundenlösung nahtlos an die (hoffentlich vorhandenen) Standards des Anbieters der Basislösung angegliedert sein muss.
Zum Schluss
Dies sind exakt die Themen, die uns umtreiben. Deshalb kommt unsere Software weitgehend ohne Abhängigkeiten von externe Softwarekomponenten aus, wenn wir diese nicht mitliefern können. Und dies ist auch weshalb unsere eigene Software stets im Quellcode, integriert in eine übergreifende Software-Logistik ausgeliefert wird.
So ist es uns möglich, jegliche Aktualisierung, Erweiterung stets im lokalen Kontext zu validieren und falls notwendig erforderliche Anpassungen auch im lokalen Kontext des Kunden vorzunehmen.
Merke: Überraschungen gibt es immer. Probleme gibt es erst, wenn man damit nicht umgehen kann.
Schließlich bleibt noch das Investitionsthema. Die Tatsache, dass eine Software vom Verwender betrieben wird muss nicht zwingend implizieren, dass eine Lizenz erworben wurde. Wenn es nur um die lokale Integration geht und keine oder nur geringe Anpassungen erforderlich sind, spricht vieles für ein Mietmodell – auch daran arbeiten wir.
(German: Die Schlosser von Morgen sind Softwareentwickler) Manufacturing companies require increasingly complex skills to maintain production and optimize operations. This is not just about saving costs, but also about having the expertise to implement complex and innovative improvements – beyond what suppliers have to offer. In the past, machines were bought for production and serviced…
(English: How to Contract a Software Developer) Wir sind ein kleines Unternehmen, das kundenspezifische Software entwickelt, die in der Regel geschäftskritische Funktionen implementiert: Back-Ends mit vielen asynchronen transaktionalen Geschäftsabläufen, Massendatenverarbeitung, Integration mit anderen Back-Ends, Maschinendaten und auch Benutzeroberflächen in der Produktion. Wir entwerfen und implementieren diese Software nicht von Grund auf. Wir verfügen über Werkzeuge, eine…
Es gibt Standardsoftware und Individualsoftware. Aus Sicht eines Kunden, der eine Software-Lizenz erwirbt bedeutet eine Individualsoftware in der Regel, dass er alle Rechte an der Software besitzt. Mit Individualsoftware bezeichnen wir in der Regel Code, der speziell auf Wunsch für einen Kunden entwickelt wurde. Als Standardsoftware bezeichnen wir dagegen Software, die vom Nutzer wohl benutzt,…
Wir sind ein kleines Unternehmen, das kundenspezifische Software entwickelt, die in der Regel geschäftskritische Funktionen implementiert: Back-Ends mit vielen asynchronen transaktionalen Geschäftsabläufen, Massendatenverarbeitung, Integration mit anderen Back-Ends, Maschinendaten und auch Benutzeroberflächen in der Produktion.
Wir entwerfen und implementieren diese Software nicht von Grund auf. Wir verfügen über Werkzeuge, eine solide Softwarebasis und Erfahrung, um Geschäftsprozesse zu analysieren, sie in Software abzubilden und schließlich zu implementieren. Das bringen wir mit.
Im Allgemeinen führen wir keine Projekte zu Festpreisen durch. Das tun wir nicht, weil es im Allgemeinen einfach keinen Sinn macht – nicht für uns, nicht für unsere Kunden.
In diesem Beitrag geht es darum, warum es in den meisten Fällen falsch ist, nach einem Festpreisprojekt zu fragen – für uns als Entwickler und für Sie als Kunde. Es geht darum, warum Sie einen Entwickler nicht für ein Festpreisprojekt beauftragen sollten, und was Sie stattdessen tun sollten – um das Leben für Sie als Kunde und uns als Entwickler besser zu machen.
Grundsätzliches
Normalerweise liest man, dass der allererste Schritt eines jeden Softwareprojekts darin besteht, ein Verständnis für das eigentliche Geschäftsproblem, seine wesentlichen Datenbeziehungen und die Benutzeranforderungen an ein Softwaresystem zu entwickeln.
Zwar gibt es eine anfängliche Problembeschreibung, aber diese beschreibt das zu lösende Problem nicht unbedingt in Begriffen, die sich leicht auf einen technischen Lösungsansatz übertragen lassen. Sie müssen also eine technischere und grundlegendere Formulierung des zu lösenden Geschäftsproblems erstellen, um eine Grundlage zu schaffen, auf der das Projekt geplant und umgesetzt werden kann.
Aber das ist nicht die ganze Geschichte. Wenn Sie an diesem Punkt angelangt sind, befinden Sie sich bereits im Projekt. Ein unverzichtbarer erster Schritt ist der Aufbau einer gemeinsamen Vertrauensbasis zwischen Kunde und Entwickler.
Warum sollte ein Kunde einem Entwickler ein Softwareprojekt anvertrauen, das sich möglicherweise zu einem millionenschweren Unterfangen entwickelt, das auf einem Austausch von Designideen und einer vagen Planung beruht?
Warum sollte ein Softwareentwickler einen teuren Rechtsstreit riskieren, weil er nicht verstanden hat, was eine Lösung er für ein millionenschweres Softwareprojekt auf der Grundlage eines Entwurfs liefern soll, der sich als Wunschdenken herausgestellt hat?
Den Zeitlauf verstehen und den Erfolg absichern
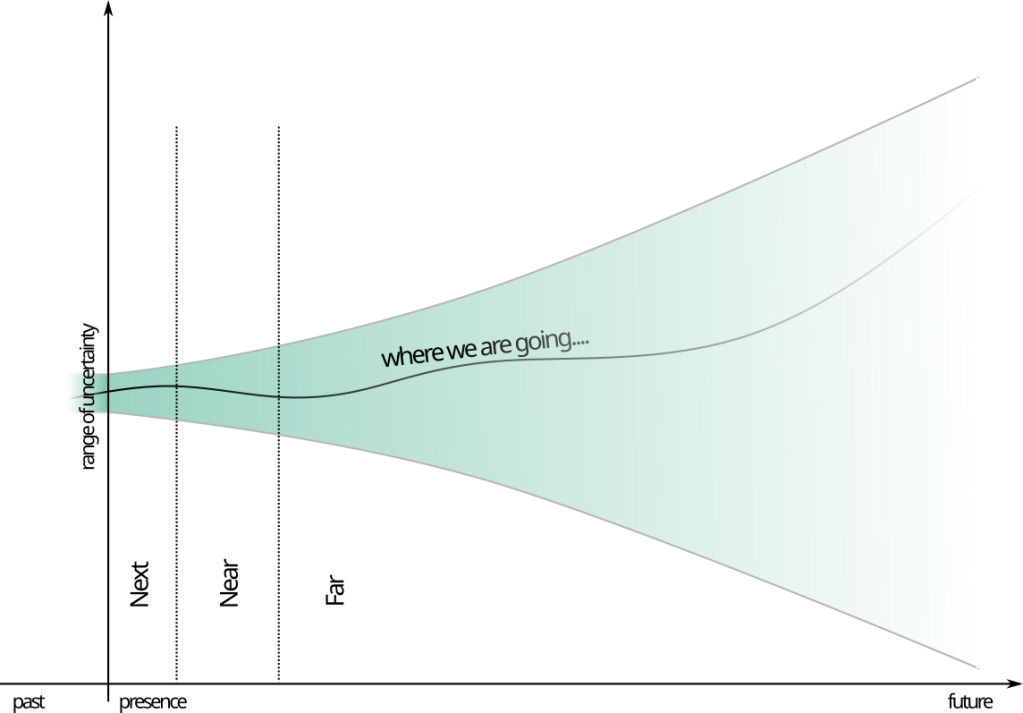
Ich glaube, dass es in jedem Projekt drei wesentliche (bewegliche) Meta-Meilensteine gibt:
Nächstes: Alle Funktionen und Korrekturen, von denen Sie wissen, dass sie benötigt werden, und von denen der Entwickler weiß (oder zu wissen glaubt), wie man sie richtig umsetzt. Alles im Nächsten kann jetzt gemacht werden.
Bald: All die Funktionen, die Ihrer Meinung nach in Zukunft realisiert werden könnten, möglicherweise in Verbindung mit dem Nächsten, die Sie für sehr nützlich halten, von denen Sie aber nicht sicher sind, ob Sie wirklich bereit sind, dafür zu bezahlen, und bei denen sich Ihr Entwickler nicht sicher ist, wie lange es dauern wird, und wie gut sie funktionieren werden.
Ferne: Die Vision von dem, was man tun könnte, wenn man das Nächste und etwas vom Baldigen hätte, und vielleicht eine coole Idee und den richtigen Geschäftsrahmen. Man weiss nicht, wie man das jetzt planen soll, aber wenn man den Gedanken mit anderen teilt, erhält man eine Orientierung, wohin wir letztendlich gehen wollen.
Diese Meta-Meilensteine als bewegliches Ziel bilden die Grundlage für die wiederholte Planung und Umsetzung. Indem wir uns auf sie einigen, schaffen wir ein gemeinsames Verständnis darüber, wie wir glauben, dass das Projekt vorankommen soll – und verpflichten uns gleichzeitig, den nächsten “realistischen” Teil davon zu erreichen:
Das Bald definiert das Nächste, indem es Ihnen die Grenze dessen aufzeigt, wovon Sie sich sicher fühlen. Das Ferne wiederum leitet die Schaffung des Nahen und die Vision, die zu kommunizieren ist, wenn man die Bemühungen als Ganzes rechtfertigt.
Während der Arbeit am Nächsten werden das Baldige und das Ferne klarer – im Idealfall fließt das Baldige in das Nächste. und es gibt ständig Nahrung für die Arbeit und den Erfolg im Projekt.
Die Sache ist jedoch folgende:
Während man sich auf das Baldige einigt und das Ferne kommuniziert, schließt man nur einen Vertrag über das Nächste ab.
Während Sie am Nächsten arbeiten, füllen Sie es wieder mit dem Baldigen auf.
Sie stellen sicher, dass eine Trennung der Vertragsparteien zwar nicht wünschenswert ist, aber nicht mehr verbrannte Erde hinterlässt als das aktuelle Nächste.
In der Praxis
Als potenzielle Projektpartner sollten sich Entwickler und Kunde auf eine erste Reihe von Nah- und Fernprojekten einigen. Ich neige dazu, sie als Phase 1 und Phase 2 zu bezeichnen, da dies wahrscheinlich eher erwartet wird. Das erste, was zu tun ist, ist ein erstes High-Level-Design oder sogar so etwas wie eine Spezifikation zu erstellen, die das Nächste genau definiert.
Das sollte die erste Verpflichtung sein.
Das Ergebnis der Spezifizierung wird ein verfeinertes Nächstes, Baldiges und möglicherweise auch ein aktualisiertes Fernes sein. Die Zielpfosten werden sich verschoben haben, und Sie können zur nächsten Iteration übergehen: Die tatsächliche Implementierung des Nächsten.
Im Sinne der agilen Entwicklung: Eine Iteration ist hier im Allgemeinen kein Sprint, sondern eher mehrere Sprints, je nach Größe des Projekts und des Planungshorizonts. Dennoch würden Sie die Budgetierung und die mittelfristige Planung auf die Sprintgrenzen abstimmen, um die Arbeit nicht unnötig zu unterbrechen.
Sie stellen jederzeit sicher, dass die Arbeiten spezifiziert und die Dokumentation so weit aktualisiert wurde, dass die Arbeiten bei Bedarf weitergegeben werden können.
Als Entwickler wissen Sie, dass alles vorbereitet ist und Sie keine (unerwarteten) technischen oder dokumentarischen Unzulänglichkeiten haben, die Sie später heimsuchen werden.
Als Kunde wissen Sie, dass es keine unnötigen Abhängigkeiten gibt, die dazu führen könnten, dass Sie die Kontrolle über Ihre Investition verlieren.
Dies bedeutet insbesondere:
Verträge stellen sicher, dass alles, was entwickelt wird, dem Kunden gehört.
Falls erforderlich, kann der Kunde die Entwicklung mit einem anderen Team fortsetzen, neue Entwickler einstellen oder die Entwicklung intern verlagern, falls dies gewünscht wird.
Letzteres bedeutet, dass die Tools für die Projektorganisation und die Inhalte sowie die Entwicklungs- und Testinfrastruktur entweder bereits vom Kunden betrieben werden, mit dem Projekt geliefert werden oder vom Kunden leicht neu erstellt werden können.
Am besten ist es natürlich, wenn die Entwicklung und das Testen in den Projektquellen enthalten und weitgehend unabhängig von anderen externen oder urheberrechtlich geschätzten Tools sind.
Um das Vertrauen in das Projekt und in Sie als Entwickler aufrechtzuerhalten, sollten Sie darauf achten, einen gut gefüllten Backlog für das Baldige zu verwalten, damit die Kontinuität des Projekts gewahrt bleibt.
Es gibt Standardsoftware und Individualsoftware. Aus Sicht eines Kunden, der eine Software-Lizenz erwirbt bedeutet eine Individualsoftware in der Regel, dass er alle Rechte an der Software besitzt. Mit Individualsoftware bezeichnen wir in der Regel Code, der speziell auf Wunsch für einen Kunden entwickelt wurde.
Als Standardsoftware bezeichnen wir dagegen Software, die vom Nutzer wohl benutzt, in der Regel aber nicht verändert oder gar vervielfältigt und vertrieben werden darf.
Soweit so klar. Oder auch nicht. Wenn man jede Software mit gleichem Aufwand, Preis, Qualität und Wartung als Individualsoftware haben könnte – nun, dann würde es den Begriff „Standardsoftware“ gar nicht geben.
Software als strategisches Investment
Individualsoftware kann viele Vorteile haben: Der Code gehört dem Auftraggeber, der alle Freiheiten hat damit zu tun, was ihm beliebt. Der Auftraggeber sitzt am Steuerrad!
Es gibt aber auch Nachteile: Bezahlt nur einer, bezahlt er mehr. Gelingt die Software überhaupt? Software braucht Betrieb, Wartung und Weiterentwicklung. Gibt es einen sicheren Partner dafür? Kann oder soll Wartung und Entwicklung selber übernommen werden?
Gerade Letzteres kann sich mittelfristig als großer Vorteil herausstellen: Alle Industrien werden Softwarelastiger und Software Know-How eine wichtige Expertise (siehe auch [Die Schlosser von morgen sind Software-Entwickler]). Die Individualentwicklung mit einem Partner kann genutzt werden, um interne Kompetenz risikoarm aufzubauen und für die Zukunft abzusichern.
Individualsoftware macht nur dann Sinn, wenn sie strategisch ist! Strategisch ist sie, wenn sie das Geschäftsmodell ermöglicht oder hinreichend verbessert und für die Zukunft absichert.
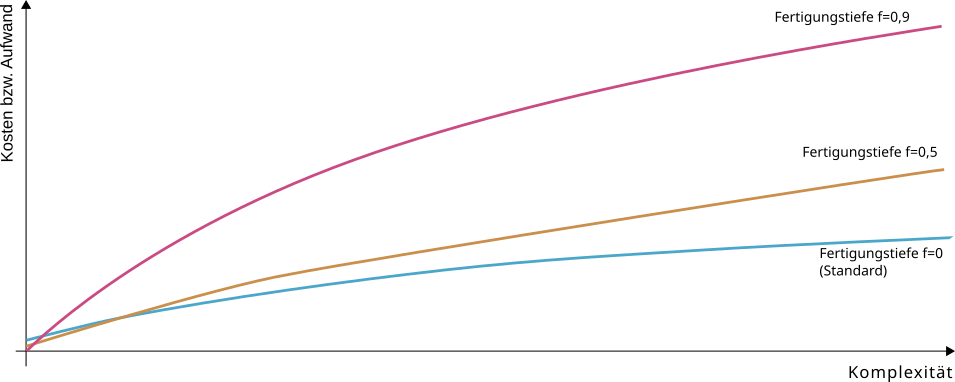
Fertigungstiefe
Ein wichtiger Faktor, der das Kosten-Nutzen-Verhältnis und das Wartungsrisiko beeinflusst ist der Anteil des speziell entwickelten Codes an der eigentlichen Lösung. Gewissermaßen die „Fertigungstiefe“.
Keine Software die heute entwickelt wird fußt nicht zu einem Großteil auf vorhandene Bibliotheken, Frameworks, und grundsätzlicher Technologien wie Betriebssystemen, Datenbanken, und einer Unmenge an Konventionen und Standards.
Die Verfügbarkeit von verwendbaren Technologien eröffnen eine enormen Raum an Möglichkeiten. Das ist aber häufig gar nicht von Vorteil. Noch besser ist, wenn bereits ein vorhandener Anwendungsrahmen – gewissermassen ein Chassis – vorhanden ist, in dem eine neue Spezialisierung implementiert wird, ohne dass grundlegende Fähigkeiten für den Geschäftseinsatz wie z. B. Stammdaten-, Benutzer- und Rechteverwaltungen neu erfunden werden müssen.
Planen Sie eine Erweiterung einer SAP Lösung, dann müssen sie sicher nicht ein neues Materialwirtschaftssystem entwickeln.
Das Ziel ist es, sich möglicht mit dem eigentlichen Problem zu beschäftigen – und nicht das Rad neu zu erfinden!
Nicht von Vorne anfangen. Eine Basis wählen, die schon zum geplanten Einsatz passt.
In eigener Sache
Was ich oben beschrieben habe ist unser Modell.
Wir bieten technologische Basis, die durch starke Modularisierung und Software-Logistik, den idealen Unterbau für anpassbare und erweiterbare on-premise Software ergibt.
Wir bieten einen Applikationsrahmen, der viele Entscheidungen vorwegnimmt und grundlegende Business-Funktionalitäten mitbringt.
Wir befähigen unsere Kunden, die Dinge soweit in die Hand zu nehmen, wie sie mögen und springen ein sobald es nötig ist.
Produzierende Betriebe müssen immer komplexere Qualifikationen mitbringen, um ihre Produktion am Laufen zu halten und optimal zu betreiben.
Hier geht es nicht nur darum, Kosten zu sparen, sondern auch darum, die Kompetenz zu haben, komplexe und innovative Verbesserungen umzusetzen – jenseits dessen, was Lieferanten zu bieten haben.
Früher hat man Maschinen für die Produktion gekauft und vom Lieferanten warten lassen. Dann hat man verstanden, dass es nicht nur günstiger sondern auch klüger ist, die Wartung selber zu unternehmen. Von der Fähigkeit, die Wartung selber durchzuführen ist es kein unüberwindbarer Schritt, die Kompetenz zu erlangen, Maschinen zu erweitern, zu ergänzen und Produktionsprozesse im eigenen Sinne zu optimieren und zu integrieren.
Ganz genauso verhält es sich heute mit der betrieblichen Software. Hat man zunächst Branchenlösungen entwickeln lassen oder von der Stange gekauft und anpassen lassen, so ist der nächste Schritt, die Kompetenz zu erlangen, die Software selber zu erweitern, zu ergänzen oder sogar zu modifizieren.
Während das bei ERP Lösungen (insb. SAP) schon immer explizit möglich war, ein absolut signifikanter Faktor für den lang anhaltenden Erfolg von SAP, so ist das bei anderer Software immer noch die Ausnahme.
Gerade für den Einsatz in der Produktion und im Zusammenhang mit zunehmender Automatisierung ist es jedoch extrem relevant, Software-Lösungen nicht nur miteinander zu kombinieren, sondern auch in der Lage zu sein, vorhandene Lösung modifizierend zu erweitern und bestenfalls komplett zu beherrschen.
Nur mit dieser Fähigkeit, wird man in der Zukunft betriebliche Prozesse komplett beherrschen können. Und nur dann ist es möglich, diese nach Wunsch anzupassen und für den geschäftlichen Erfolg zu gestalten.
We know that our ability to create abstractions is key to manage complexity – in life, in science, in mastering technology. Without creating abstractions we would not be able to make sense of our daily routine, what we work on, and much less of the constant sensory input we receive.
In fact, I doubt that anybody can meaningfully keep track of more than a handful interconnected things while “thinking”. That is why powerpoint presentations explaining a concept should never have more than three boxes with arrows between them – nobody will buy your idea otherwise. Likewise, any concept described by three connected boxes look convincing for most people – most likely the true reason for the demise of countless companies.
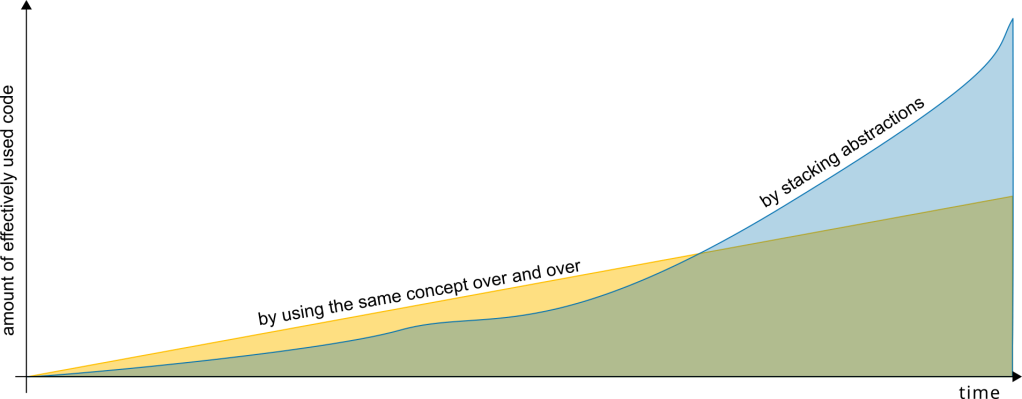
Abstractions are essential to software development. Not only that the whole idea of software requires some serious level of abstraction, but thankfully programming languages provide the means to stack abstractions on top of each other – leading to libraries of libraries of concepts and abstractions borrowed from those around and before us allowing us to create software that encompasses many millions, if not billions of lines of code – while writing only a fraction of that by ourselfs.
All that while being mostly ignorant to the intricacies of the lower layers of the pile of abstractions (actually the shoulders of the giants) we are standing on. So much so, that something like a file system occurs to us as natural a concept as, say, a horse.
And here is the catch: Because any layer of abstraction is hiding a number of lower level concepts, and since that number is naturally at least two (otherwise: Why bother?), the sum of lower level abstractions made tangible by introducing higher level concepts essentially growth exponentially.
Not very scientifically speaking, for code this means:
However the same pattern applies to other realms, be it running an organization or taking care of business or being a school teacher. Somebody good at computing does not necessarily make a good mathematician while being good at computing is not at all required to be a good mathematician. The ability to understand, create, and apply abstractions hands down wins over any “increased clock speed”.
In other words: As long as we are good at building abstractions, it’s ok that we cannot handle more than three boxes with arrows per slide….
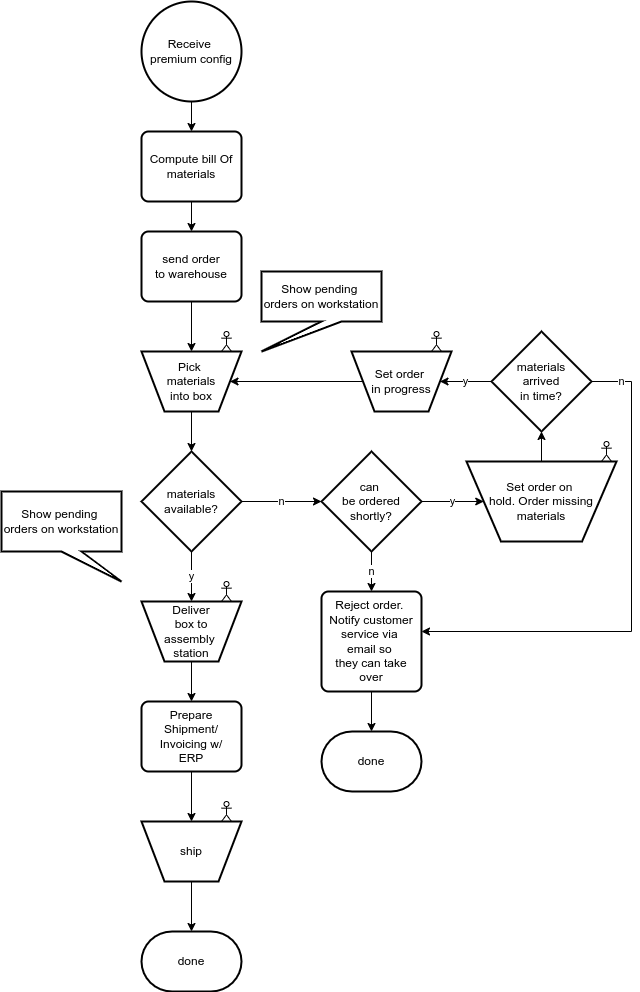
Imagine you are a high volume manufacturer of vacuum cleaners. Everything runs smoothly, but you feel there may be some business potential for configurable high end vacuum cleaners that are built to spec.
You image a GOLD series of vacuum cleaners for which customers can configure various color schemes and decorations, various sensor add-ons, GPS tracking, and other features that a certain high-profile customer group finds exciting.
Of course, ordering a GOLD configuration from the web site comes at a premium.
Problem is: Your current production process does not accommodate for an ad hoc built-to-spec production. If you cannot reliably produce it, you cannot sell it!
So you come up with a pragmatic process, that makes sure you can track from order to shipment and that everything is consistent with your ERP recorded data. For example something like this (that I just made up – and you will get the point I suppose):
Obviously this requires some software support. It is not huge, but it may need to evolve and go through changes when you evolve your business. Who knows, maybe one day you will want to inform your customers on the production progress of there GOLD product.
Unfortunately you do not have much software development expertise in-house. So where do you get that software from? Do you ask your ERP supplier? Do you ask your Production Automation / MES supplier? Maybe not. Both are not exactly into custom development and will only increase your lock-in with them.
You could ask a software development agency – maybe even something really cheap with developers elsewhere but a local project manager.
Problem is: You might get a great solution but it will be a one-off solution. Who is going to maintain it, if the team that developed it will break up and join other projects right after? How do make sure, you can maintain it later?
The catch is:
You need to own it, if you want to make it!
Developing appropriate software development expertise is difficult. Developing and maintaining a custom business application that manages some long running workflows and integrates with legacy systems in a manageable way is different from developing a Web site. So you should look for a partner that provides
The expertise to build a solution;
A blueprint on how to extent and expand the solution into YOUR business platform;
A technology platform that you can build on, and
Support when you feel it is time to take over
This is the essence of digital transformation: It is not about creating digital versions of processes you already have, it is about making use of digital capabilities to implement new business models or process optimizations that were simply not possible before.
Please check out the great article by Volker Stiehl linked below.
Eventually you will need to bring your code into productive use – i.e. you need to make sure it is executed and accessible for users or systems that want to interact with it.
That will involve some form of deployment, maybe automatically or semi-automatically – nothing I really want to talk about here.
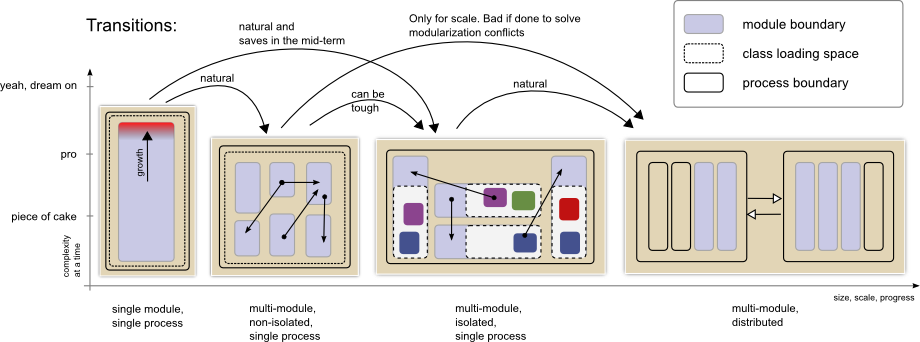
What I want to talk about is whether and for what reasons you may want to consider a system setup that involves deployment to more than one execution environments that interact, if at all, via a network boundary. In other words we are talking about distribution as in Distributed Systems or, more specifically, Micro-Services.
To cut things short: The point that I want to make is that you should not distribute except for non-functional reasons – which in many instances require much less distribution consideration than you may be led to believe.
Good Reasons for Distributed Architecture
In an ideal world there would be just one all-encompassing code execution environment and all code we conceive would just be put there to solve the problem it was designed for. We would not worry about reliability, security, availability, performance. But that is obviously not the case.
Throughput: If your code needs to perform a lot of work, a single piece of hardware may not be enough to achieve the required throughput. In that case, you want to scale out (horizontally). That is you want to make your code run on multiple machines to perform more work in parallel.
Security: Some aspects of your code may need access to sensible data while other parts do not need such access. In that case you may want to have corresponding control flows performed in isolated environments that meet higher security requirements for access and maintenance.
Availability: Your code may serve under different quality of service expectations. For example some customers may be paying a premium to have top performance while others would be willing to accept some lagging performance during peak usage. Likewise you may want that some very demanding workload does not impact performance of end user interfaces. In both cases, driven by external requirements such as type of users or type of workload, you will want to separate workloads to different environments.
Bad Reasons for Distributed Architecture
So that was clear, right? In order to identify some bad reason for distributed deployments let’s make a thought experiment. Imagine we have some logical module “Order Management”, which is all about managing orders for something. We do not really care – but we are short on imagination and this is one of the typical examples. So, there are some aspects that make up our order management:
Let’s – for simplicity and to make sure you think beyond implementation code – call this the Order Management Module. Looking at this somewhat cohesive picture, you might think that it would be a good idea to turn the Order Management Module into an Order Management System that is deployed on its own and that others integrate with via remote APIs – i.e. a Microservice.
Let’s run some what-if experiments on that:
Availability: If Order Management is down but our DB is up: We cannot check on orders – just because.
Extensibility: Our system gets more complex and some other services need to be informed on order status changes to trigger some follow up workflow. Can the order management invoke my code? Nope. So we need to messaging? Yes!
Likewise: Special types of orders need extended data validation in scenarios that reuse the order management. How do these extensions get to the Order Management? And how do we enforce compatibility, if the Order Management is de-coupled from its extenders?
Scaling: Some scenario involving orders needs to be scaled out. How much do we need to scale up the individual parts like our Order Management exactly?
Refactoring: Let’s not even go there.
In short: This form of distribution comes at a high cost in terms of additional complexity due to the introduction of remote boundaries and possibly even split project management. It is almost, as if the Order Management is being developed and provided by an independent organization just like any old 3rd party system you need to integrate with.
Oh wait… it is exactly like that! Is that what you wanted?
What Happened?
We confused modularization and distribution – and essentially for no good reason but that it looked obvious in naming.
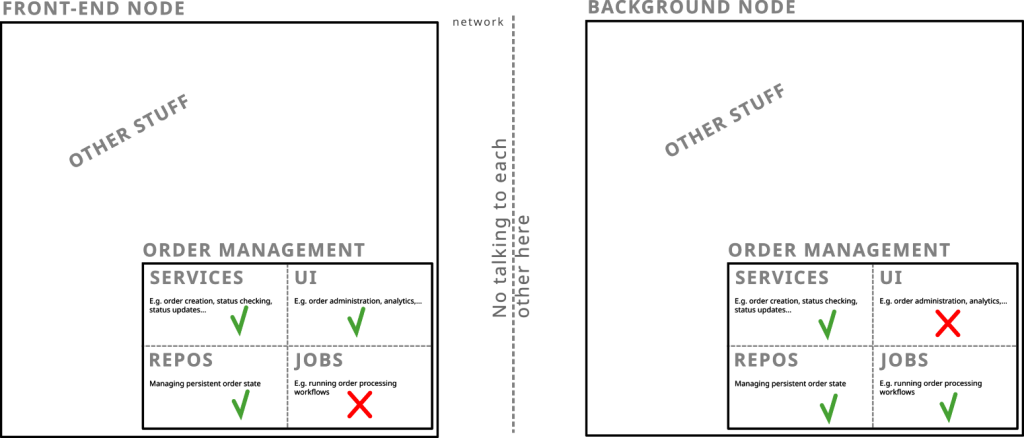
The better solution however would be to include the Order Management as a module within the system so that its capabilities are available and can potentially be part of any execution of anything in the system.
That does of course not imply that every workload or control flow should run everywhere.
For example: Probably the most obvious reason for separation is to have front-end performance not getting impacted by background work and to being able to scale background work independently from front-end work.
So our deployment would be more like this:
You can tell from the naming that we are less concerned with function but kind of function.
Indeed the Order Management as a named set of capabilities is simply integrated with the overall capabilities of the system. Checking on an order would be is directly from the front-end. Administration of the Order Management is be done directly from the front-end.
Mass checking and email notification jobs are however performed on background nodes.
If the Order Management needs to look for extensions to call, based on a type of order: That would be done in-place as part of the control flow that requires so – as by definition – it would all be part of the system and so potentially available when needed.
That is: Any kind of control flow of the system can be performed in any execution environment. We make however sure, based on smart non-functional reasoning, that this does not happen, if it violates our non-functional requirements.
Conclusion
With this post, finally that little series referenced below comes to an end. It has been a busy year so far and I did not get around to writing a lot. I will try to post some smaller pieces next.
One of the fundamental problems of software development (and not only that) is that a) humans are really bad at managing complexity and that b) that code becomes really complex quickly.
The top one reason behind code going bad is that we stop being able to grasp how it actually works so much so that we start being afraid to change it structurally (i.e. refactor it). Possibly contrary to intuition, code that reached that state is essentially a car that lost its steering and – if at all – still moves out of inertia. Not good!
Obviously there must be a way around our limited intellectual capacity – after all we see enormously complex systems at work around us. But are they?
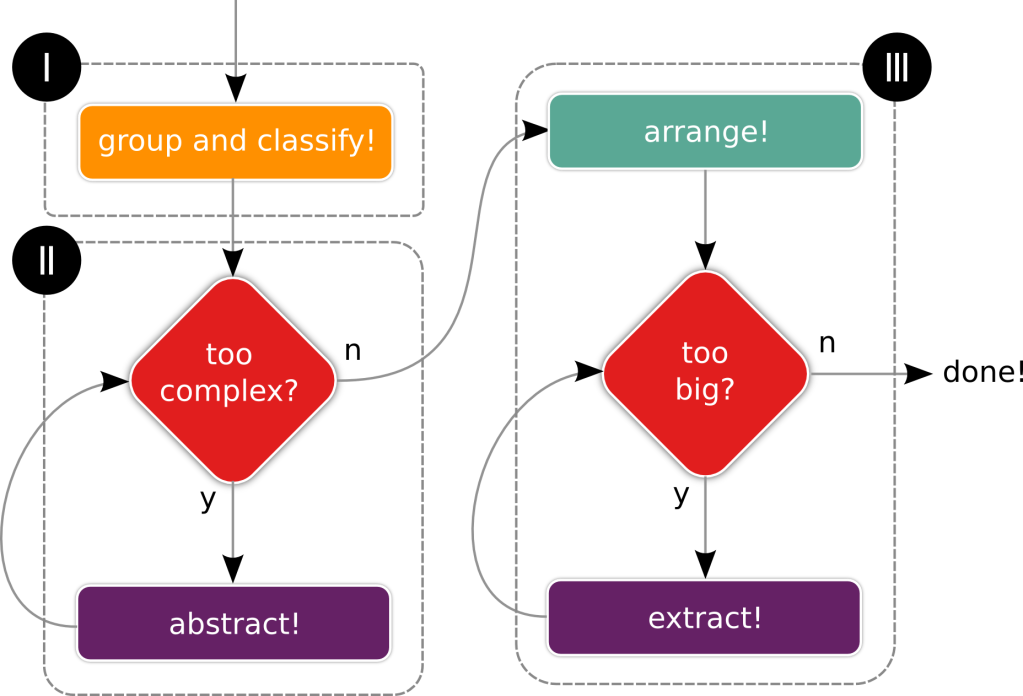
The trick to managing complexity is to avoid it. And the trick to avoid complexity is to build abstractions. Finally something we are quite good at.
Building abstractions happens everywhere from science to accounting. In software, the abstraction is a means to structure code and to decouple the code relying on an abstraction (such as a mobile app wanting to take a picture) from the details of the implementation of the abstraction (such as the hardware driver for the camera).
The same is true when creating an interface or a generic type in our favorite programming language so that we make effective use polymorphism to better structure some code.
You can look at modularization from different levels. For example as a way of structuring code of a library or application that is developed, packaged, and distributed as a whole from an (essentially) single source code folder. For example by arranging packages and folders in ways that help explain and understand responsibilities.
While maintaining a clear and instructive code structure is really important, it only carries so far. The reason is simple: As there is many, many more ways to screw up than there are to improve, any sufficiently large and non-usage-constraint code is prone to rot by violations of abstractions and complexity creep.
This kind of local (if you will) modularization is not what I am considering in this post. Instead, I am talking about moving whole slews of implementation (modules) away from your code, so that at any time the complexity you actually need to deal with is manageable.
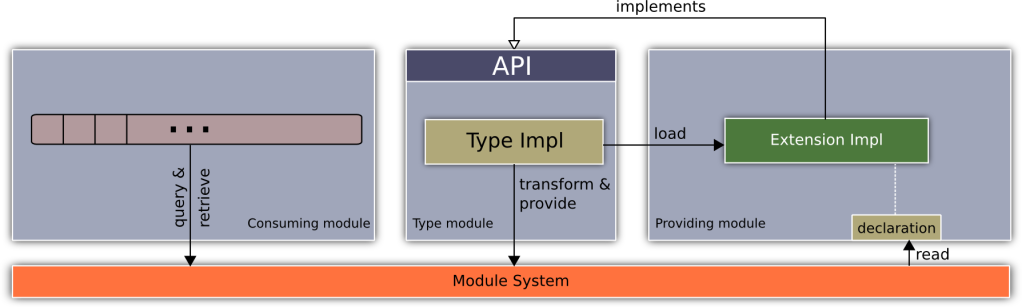
The means of modularization are abstraction, encapsulation, and information hiding. However that is actually really the outcome of:
Coming up with an API (contract)
Separating implementation details from its API (hiding details)
Making sure implementation is neither visible nor impacting other parts of the system (encapsulate)
How to Do It
I wrote a few posts on techniques and aspects of modularization. I will just enumerate the basics:
Re-Using and Extending
The two most notable patterns in contract building between modules are providing an API to be used by another module to invoke some function and, in contrast to that, providing API that is to be implemented by another module so that it can be invoked. The latter is in many ways how Object-Oriented-Programming factors into this story.
Exposing a contract means to share capabilities to be used by others. What is needed to do so however should not only be visible (so that it may not be accidentally used), it should not affect other parts of the system by its presence either.
This post looked at modularization as if it only applies to code. A good modular system should provide modularization capabilities to essentially all aspects it is used for though. If managing configuration is an important aspect, it just means that configuration can be part of modules as well. So do Web application resources or whatever else is part of what your platform of choice is typically used for. That is a core feature of the z2-environment.
Modularization is a rich topic. Doing it right, keeping a sustainable complexity level over time regardless of solution size by finding appropriate contracts and management of contracts is skillful craftmanship.
Not paying attention, a lack of willingness to invest into structural maintenance easily leads to frustrating, endless “too little, too late” activities. A growing code base built on weak isolation requires development disciplin that is unrealistic to expect in most commercial circumstances.
Getting it right, seeing it work out however is a great experience of collaborative creation that I am fortunate to have been part of!
We are a small company developing custom software that typically implements some business critical function. Actual back-ends with lots of asynchronous transactional business workflows, mass-data processing, integration with other back-ends, machine-data and shop floor user interfaces.
We do not design or implement this software from scratch. We have tools and a solid software foundation and experience to analyze business processes, map them into software and eventually implement them. That’s what we bring to the party.
We do in general not do fixed-price projects. We do not do that because – in general – that simply does not make sense – not for us, not for our clients.
This post is on why asking for a fixed-price project is more often than not the wrong thing to ask for, for us as developer and for you as client. It is on why you should not want to contract a developer for a fixed price project and what you should do instead – to make life better for you as client and us as developer.
Groundwork
Normally you will read that the very first step of any software project is to develop an understanding of the actual business problem, its essential data relationships and what users will need to solve it using a software system.
And indeed, while there will be an initial problem description, it is not necessarily describing the problem to solve in terms that map easily to a technical solution approach. So you need to create a more technical and fundamental formulation of the business problem to solve as to create a foundation onto which the project can be planned and implemented.
However that is not the whole story. When you are at that point, you are already in the project. Another indispensable step that comes first is to build ground for common trust between client and developer.
Why would a client trust a software project that potentially evolves into a multi-million euro endeavor to a developer based on an exchange of design ideas and some vague planning?
Why would a software developer risk expensive litigation because of a misunderstanding of what a solution to a million-euro software project is supposed to deliver based on a design that turned out to be wishful thinking?
Navigating the Timeline and Securing Success
I believe there are three essential (moving) meta-milestones in any project:
Next: All the features and fixes you know are needed and of which the developer knows (or believes to know) how to do them right. Everything in Next can be done now.
Near: All those features that you believe could be done down the road, possibly relying on the Next, that you think would be really useful to have but you are not sure you are really willing to pay for all them just yet nor is your developer certain how long it will take and how well it will work.
Far: The vision of what could be done, if you had the Next and some of the Near, and maybe some cool idea and the right business framework. You would not know how to plan for it now, but sharing it provides orientation of where, eventually, we want to go.
These moving target meta-milestones define the grounds on which to repeatedly plan and commit. By agreeing on them, we build a common understanding on how we believe the project is to move forward – while committing to the next “realistic” fraction of it:
The Near defines the Next by showing you the boundary of what you feel sure about. The Far on the other hand guides the creation of the Neart and the vision to communicate when justifying the effort as a whole.
While working in the Next, the Near and the Far become clearer – ideally Near flows into Next and there is constantly food for work and success in the project.
Here is the deal however:
While agreeing on the Near and communicating the Far, you only contract on the Next.
While working on the Next, you fill it up again from the Near.
You make sure that splitting up, while not desirable, leaves no more burned ground than the current Next.
Practically Speaking
As potential project partners, developer and client should agree on a first set of a Near and Far. I tend to call them Phase 1 and Phase 2, as that is probably more expected. As the first thing to do however is to come up with an initial high-level design or even somewhat of a specification, that would exactly define the Next.
And that is what should be the first commitment.
The result of the specification will be an understanding of a refined Next, Near, and possibly an updated Far as well. The goal posts will have moved, and you can move forward into the next iteration: Actually implementing the Next.
Speaking in agile development terms: An iteration here is generally not a sprint, but more likely multiple sprints, depending on the size of the project and the planning horizon. You would nevertheless align budgeting and mid-term planning with sprint boundaries as to not interrupt work unnecessarily.
At any time, you make sure that work has been specified and documentation has been updated to the extent that work can be passed on if required.
As a developer, you know that everything is set and you do not have (unexpected) technical or documentation depths that will haunt you later on.
As a client you know that there is no unnecessary dependency that may mean that you lose control over your asset.
In particular this means:
Contracts do make sure that anything developed belongs to the client
If necessary, the client can continue development with a different team, bring in new developers, move development in-house, if that is desired.
The latter means that project organization tools and content, development and testing infrastructure is either already operated by the client, comes with the project, or can easily be re-created by the client.
It is naturally best, if development and testing is inherently contained with the project sources and mostly independent of other external or proprietary tools.
In order to maintain trust versus the project and in you as a developer, you should make sure to manage a well stuffed backlog for the Near so that continuity of the project is preserved.